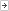在电商系统中,分布式缓存与本地缓存的选择需结合业务场景、数据特性、性能需求和一致性要求综合判断。以下从核心选型维度和典型场景匹配两方面,详细说明如何选择合适的缓存类型:
一、核心选型维度
选择缓存时需优先评估以下维度,这些维度直接决定缓存类型的适配性:
选型维度 优先选本地缓存的情况 优先选分布式缓存的情况
访问频率 超高频率(如每秒数万次,如首页 Banner) 中高频(如每秒数千次,如商品详情页)
数据量大小 数据量小(如热门商品 TOP100) 数据量大(如全量商品库、用户历史订单)
数据更新频率 低频更新(如商品分类树,每周更新一次) 高频更新(如库存、价格,每秒可能多次变动)
一致性要求 允许短期不一致(如商品描述、品牌故事) 强一致性(如库存余量、订单状态、用户余额)
是否跨实例共享 无需共享(如单实例内的临时计算结果) 必须共享(如用户登录状态、跨端购物车)
内存成本敏感度 希望控制内存成本(避免分布式缓存过度扩容) 可接受更高成本换取全局可见性

二、典型场景匹配与选择逻辑
1. 本地缓存的典型适用场景
本地缓存适合高频访问、静态 / 低频更新、非核心一致性的场景,核心逻辑是 “用空间换时间,减少分布式缓存压力”:
首页静态数据
如首页轮播图、活动 Banner、导航菜单,这些数据更新频率低(如每天更新),且被所有用户高频访问。
本地缓存可直接存储,避免每次请求穿透到分布式缓存,降低 Redis 的 QPS 压力。
示例:用 Caffeine 缓存首页 JSON 串,设置 1 小时过期,更新时通过配置中心主动触发所有实例刷新。
热门商品基础信息
如 TOP1000 热门商品的名称、主图、基础价格(非实时促销价),访问频率极高但更新少。
本地缓存可存储这些数据,减少分布式缓存的重复查询(例如:用户浏览商品列表时,直接从本地缓存返回前 100 条热门商品)。
应用内临时计算结果
如购物车的价格计算(优惠券、满减规则的组合计算)、用户标签的临时匹配结果,这些数据仅在当前请求链路中有效,无需全局共享。
本地缓存可避免重复计算(如同一请求中多次调用价格接口,直接缓存中间结果)。
分布式缓存的 “兜底备份”
秒杀、大促等峰值场景中,将核心数据(如商品库存上限)同时缓存到本地,当 Redis 宕机时,本地缓存可临时返回兜底数据(如 “库存查询中”),避免服务直接报错。

2. 分布式缓存的典型适用场景
分布式缓存适合核心业务数据、高频更新、跨实例共享的场景,核心逻辑是 “保证全局一致性,支撑跨节点业务”:
商品库存与价格
库存和实时价格是电商核心数据,必须全局一致(否则会出现超卖、价格显示错误)。
分布式缓存(如 Redis)通过原子操作(如decr)保证库存扣减的准确性,且所有实例访问到的库存数据一致。
示例:用 Redis 的Hash存储商品库存,HGET key stock获取实时余量,扣减时用HINCRBY key stock -1并判断是否为负。
用户会话与登录状态
用户登录 Token、会话信息需要跨设备 / 跨实例共享(如用户在 APP 登录后,PC 端自动识别)。
分布式缓存是唯一选择,例如用 Redis 存储 Token 与用户 ID 的映射,设置 2 小时过期,支持多端同步登录状态。
购物车数据
用户购物车需要跨端同步(APP、小程序、PC 端),且实时更新(如添加 / 删除商品)。
分布式缓存可存储购物车明细(如 Redis 的Hash存储用户 ID→商品 ID→数量),保证多端操作的一致性。
分布式锁与限流
电商中的库存扣减、订单创建等场景需要分布式锁防止并发冲突,限流(如接口 QPS 控制)需要全局计数器。
分布式缓存(如 Redis)的SET NX可实现分布式锁,INCR可实现全局限流计数,这些功能本地缓存无法支持(因多实例不互通)。

三、混合使用的关键原则
在实际电商系统中,本地缓存与分布式缓存通常配合使用,遵循以下原则最大化效率:
“本地缓存→分布式缓存→数据库” 的多级缓存链
访问数据时,先查本地缓存;未命中则查分布式缓存;再未命中则查数据库,并回填两级缓存。
例如:查询商品详情时,先从 Caffeine 查本地缓存,未命中则查 Redis,最后查 MySQL,查询后同时写入本地缓存(短期过期)和 Redis(长期过期)。
本地缓存存储 “子集”,分布式缓存存储 “全集”
本地缓存只存高频访问的小部分数据(如 TOP1000 商品),避免内存溢出;分布式缓存存储全量数据(如百万级商品)。
示例:商品库有 1000 万商品,本地缓存只存访问量前 1% 的 10 万条,其余 990 万存在 Redis。
本地缓存设置 “短过期”,减少一致性风险
本地缓存过期时间通常设为分钟级(如 5-30 分钟),分布式缓存设为小时级,通过时间差减少多实例数据不一致的影响。
例如:商品分类信息本地缓存 10 分钟过期,Redis 缓存 2 小时,即使本地缓存不一致,10 分钟后会自动刷新为最新值。
核心数据优先保证分布式缓存一致性
库存、价格等核心数据,本地缓存仅作为 “降级备份”,且必须从分布式缓存同步(如启动时预加载、定时拉取最新值),避免独立维护。
总之,选择的核心逻辑是:用本地缓存解决 “速度与压力” 问题,用分布式缓存解决 “一致性与共享” 问题。电商系统需根据数据的 “重要性”“访问频率”“更新频率” 分层设计,通过多级缓存配合,在性能、一致性和成本之间找到平衡。
|
||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||
|